
字符编码和中文乱码分析
一. 编码类型
1. ASCII
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码),是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。其最高位(b7)用作奇偶校验位,后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8位用于确定附加的128个特殊符号字符、外来语字母和图形符号。
2. ISO-8859-1
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
3. GB2312
全称《信息交换用汉字编码字符集·基本集》,是双字节编码。GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
4. GBK
GBK全称《汉字内码扩展规范》,它的出现是为了扩展 GB2312,加入更多的汉字,包括繁体字。它的编码是和 GB2312 兼容的。
注意:gbk和gb2312的中文都是两个字节,英文(半角的)一个字节。
5. GB18030
是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。
unicode
虽然通过使用不同字符集,我们可以在一台机器上查阅不同语言的文档,但是我们仍然无法解决一个问题:在一份文档中显示所有字符。为了解决这个问题,我们需要一个全人类达成共识的巨大的字符集,这就是Unicode字符集。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
虽然每个字符在Unicode字符集中都能找到唯一确定的编号(字符码,又称Unicode码),但是决定最终字节流的却是具体的字符编码,如utf-16或utf-8。例如同样是对Unicode字符“A”进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。
6. UTF-16
UTF-16 是 Unicode 字符在计算机中存取方法的一种具体编码。UTF-16支持Unicode全字符集的编解码,采用了变长编码,最少使用2个字节,如果要编码BMP以外的字符,则需要4个字节结对。当然,一般用BMP字符就够了,因此在网上很多都写utf-16是两个字节。
7. UTF-8
UTF-8应该是目前应用最广泛的一种Unicode编码方案。由于UCS-2/UTF-16对于ASCII字符使用两个字节进行编码,存储和处理效率相对低下,并且由于ASCII字符经过UTF-16编码后得到的两个字节,高字节始终是0x00,很多C语言的函数都将此字节视为字符串末尾从而导致无法正确解析文本。
对于ASCII字符的编码使用单字节,和ASCII编码一摸一样,这样所有原先使用ASCII编解码的文档就可以直接转到UTF-8编码了。对于其他字符,则使用2-4个字节来表示,其中,首字节前置1的数目代表正确解析所需要的字节数。
UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,相比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
二. java中的编码
在JVM内,从class文件加载的源码全部以UNICODE编码。在内存中倒腾String等数据是编码无关的,但是程序本身难免牵涉到外部文件的读写(如xml,properties文件等)、与数据库的交互、网络数据流读写等。这样就会造成很多非unicode编码的字符存在于JVM中,这也就是乱码出现的根本原因所在。
在使用IDE进行开发时,比如ECLIPSE,IDEA等,可以指定源文件(.java)的编码格式,此处的编码格式是指Java文件自身的编码。而xml、jsp、html等文件是能够自身描述文件编码的。xml可以通过encoding来指定编码方式,而html通过content-type方式来指定,如果打开这些文件,就会调用相应的编码方式来处理。但是经过javac命令编译后,生成的.class文件毫无疑问都是Unicode编码。
jvm在各个阶段都编码方式如下图所示:
在存储java源文件时,是按照java文件的编码对文件进行编码,然后存储在磁盘中。当要对java源文件进行编译时,用源文件的编码对其进行解码,编译生成的class文件为unicode的编码方式。最终jvm加载class文件执行到jvm中,在jvm中的编码方式也是unicode。
在java中,主要用以下两个方法来对String进行编解码:
- getBytes(String charset)
将字符串按照指定的charset编码,返回其字节方式的表示。具体来说,实现的是从unicode—>charset的转变。 - new String(byte[] bytes,String charset)
将字节数组按照charset进行识别,最终转化为Unicode存储在JVM内,编码是从charset->unicode的转变。
例如如下的例子:1
2
3String a="中文";//当然你可以以unicode的形式写成String a="\u4E2D\u6587";
byte[] bs = a.getBytes("gbk");
String b= new String(bs,"iso-8859-1");//如果这里使用gbk编码进行解码的话,会自然的得到原来的a。
可以看出这个时候已经为乱码了,不过由于没有信息丢失,所以还是可以恢复成中文的。
恢复的过程为 String c = new String(b.getBytes("iso-8859-1"),"gbk");
这种方式中间多了两次编解码,不推荐使用。
三. web编码
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。这些过程如下图所示: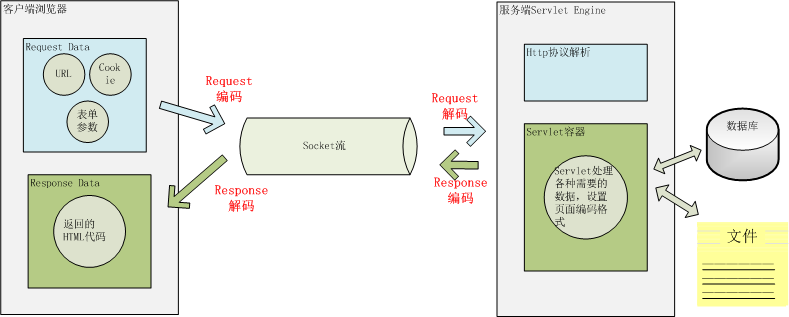
1. request编码
URL的几个组成部分如下图所示: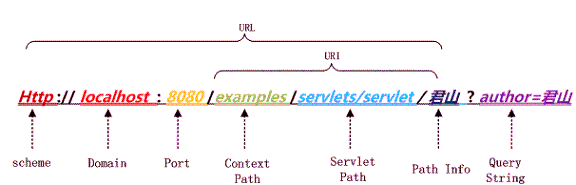
上图中以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
Port 对应在 Tomcat 的 <Connector port="8080"/> 中配置,而 Context Path 在 <Context path="/examples"/> 中配置,Servlet Path 在 Web 应用的 web.xml 中的。注意这里是在浏览器里直接输入 URL 所以是通过 Get 方法请求的,如果是 POST 方法请求的话,QueryString 将通过表单方式提交到服务器端。
a.URI
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号,这是因为网络标准RFC 1738做了硬性规定:
“只有字母和数字[0-9a-zA-Z]、一些特殊符号”$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致”URL编码”成为了一个混乱的领域。由于不同浏览器可能采取不同的编码方式,因此url最好不要有中文字符;对于那些用js或模拟浏览器方式请求的(如httpclient),可以将url进行编码再提交,这样就能够得到控制。
在java中有URLEncoder.encode(String s,String enc)/URLDecoder.decode(String s,String enc)等方法,在javascript中有escape/unescape,encodeURI/decodeURI,encodeURIComponent/decodeURIComponent等方法。
b.POST
POST 表单参数传递方式是通过 HTTP 的 BODY 传递到服务端的。当我们在页面上点击 submit 按钮时浏览器首先将根据 ContentType 的 Charset 编码格式对表单填的参数进行编码然后提交到服务器端。
2. request解码
在服务器收到浏览器发来的请求后,需要对一些内容进行解码:
a.URI
对 URL 的 URI 部分进行解码的字符集是在 connector 的 <Connector URIEncoding=”UTF-8”/> 中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
b.GET
GET方式的请求,QueryString 的解码字符集要么是 Header 中 ContentType 中定义的 Charset 要么就是默认的 ISO-8859-1,要使用 ContentType 中定义的编码就要设置 connector 的 <Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true”/>中的 useBodyEncodingForURI 设置为 true。这个配置项的名字有点让人产生混淆,它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码。设置了URIEncoding=“UTF-8”这样也可以。若useBodyEncodingForURI和URIEncoding同时设置了,useBodyEncodingForURI优先级高于URIEncoding。
c.POST
在服务器端同样也是用 ContentType 中字符集进行解码。所以通过 POST 表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过 request.setCharacterEncoding(charset) 来设置。post方式的编码跟useBodyEncodingForURI和URIEncoding没关系。
d.header
Header中传递的其它参数如 Cookie、redirectPath。对 Header 中的项进行解码也是在调用 request.getHeader 是进行的,如果请求的 Header项没有解码则调用 MessageBytes 的 toString 方法,这个方法将从 byte 到 char 的转化使用的默认编码也是 ISO-8859-1,而我们也不能设置 Header 的其它解码格式,所以如果你设置 Header 中有非 ASCII 字符解码肯定会有乱码。
3. response编码
当用户请求的资源已经成功获取后,这些内容将通过 response 返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码。这个过程的编解码字符集可以通过 response.setCharacterEncoding 来设置,它将会覆盖 request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端。服务器按照response.setCharacterEncoding—contentType—pageEncoding的优先顺序,对要发送的数据进行编码。
4. response解码
浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的 <meta HTTP-equiv="Content-Type" content="text/html; charset=GBK" /> 中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。
注意:
- GET 方式 HTTP 请求的 QueryString 与 POST 方式 HTTP 请求的表单参数都是作为 Parameters 保存,都是通过 request.getParameter 获取参数值。对它们的解码是在 request.getParameter 方法第一次被调用时进行的。所以request.setCharacterEncoding 应该设置在request.getParameter之前。
在java web开发中经常会添加filter来设置字符编码,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>在CharacterEncodingFilter里面,会执行
request.setCharacterEncoding('UTF-8')的操作。该filter要设置在其他filter之前,否则可能不起作用,因为解码是在 request.getParameter 方法第一次被调用时进行的,如果其他filter通过request获取了参数,那么就解码了,再给request设置编码就不起作用了。- URIEncoding就是针对请求参数get的编码设置的,而filter的
request.setCharacterEncoding('UTF-8')或者请求header中的content-type中的编码都是针对请求体的,不影响get方式的请求。 - 在jsp中
<%@page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>, pageEncoding和contentType都可以设置JSP源文件和响应正文中的字符集编码,但:
设置JSP源文件字符集时,优先级为pageEncoding>contentType。如果都没有设置,默认ISO-8859-1。
设置响应输出的字符集时,优先级为contentType>pageEncoding。如果都没有设置,默认ISO-8859-1。 - jsp编译成servlet步骤:
第一步将jsp编译成.java:用pageEncoding编码来解码jsp文件,解码成unicode,转成servlet的java文件,用utf-8进行编码存储;
第二步用javac将java源码编译成.class文件:用utf-8解码java源码,转成unicode编码的class文件。
