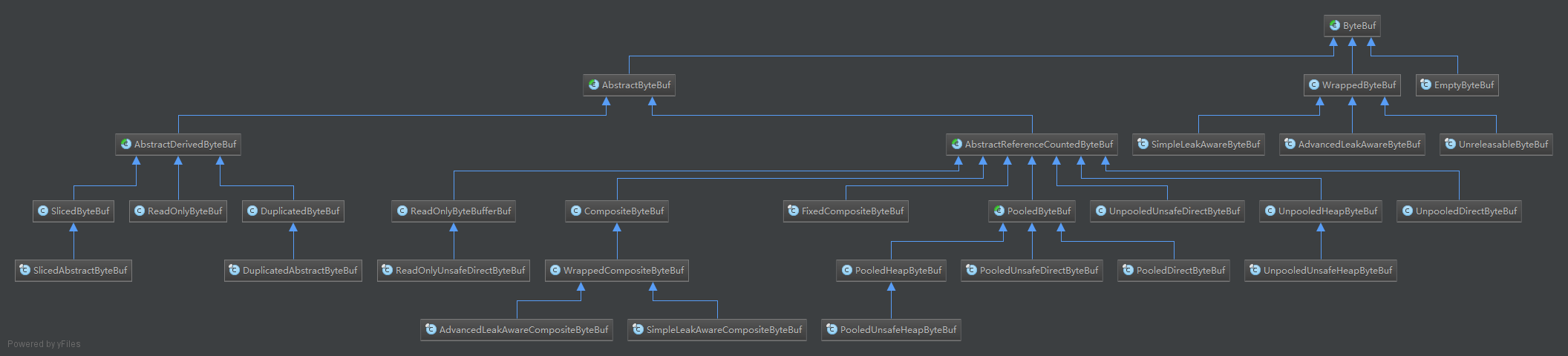
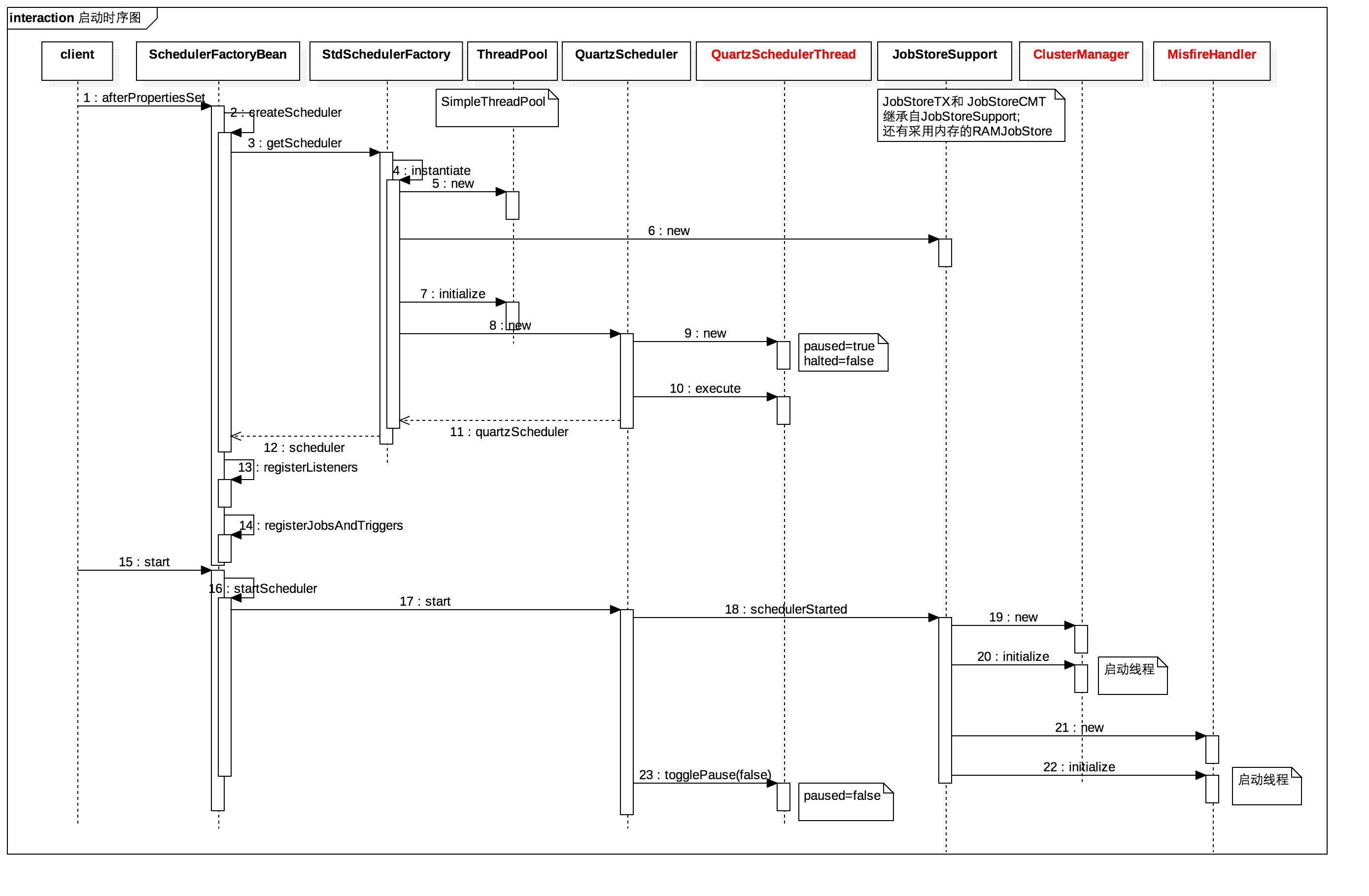
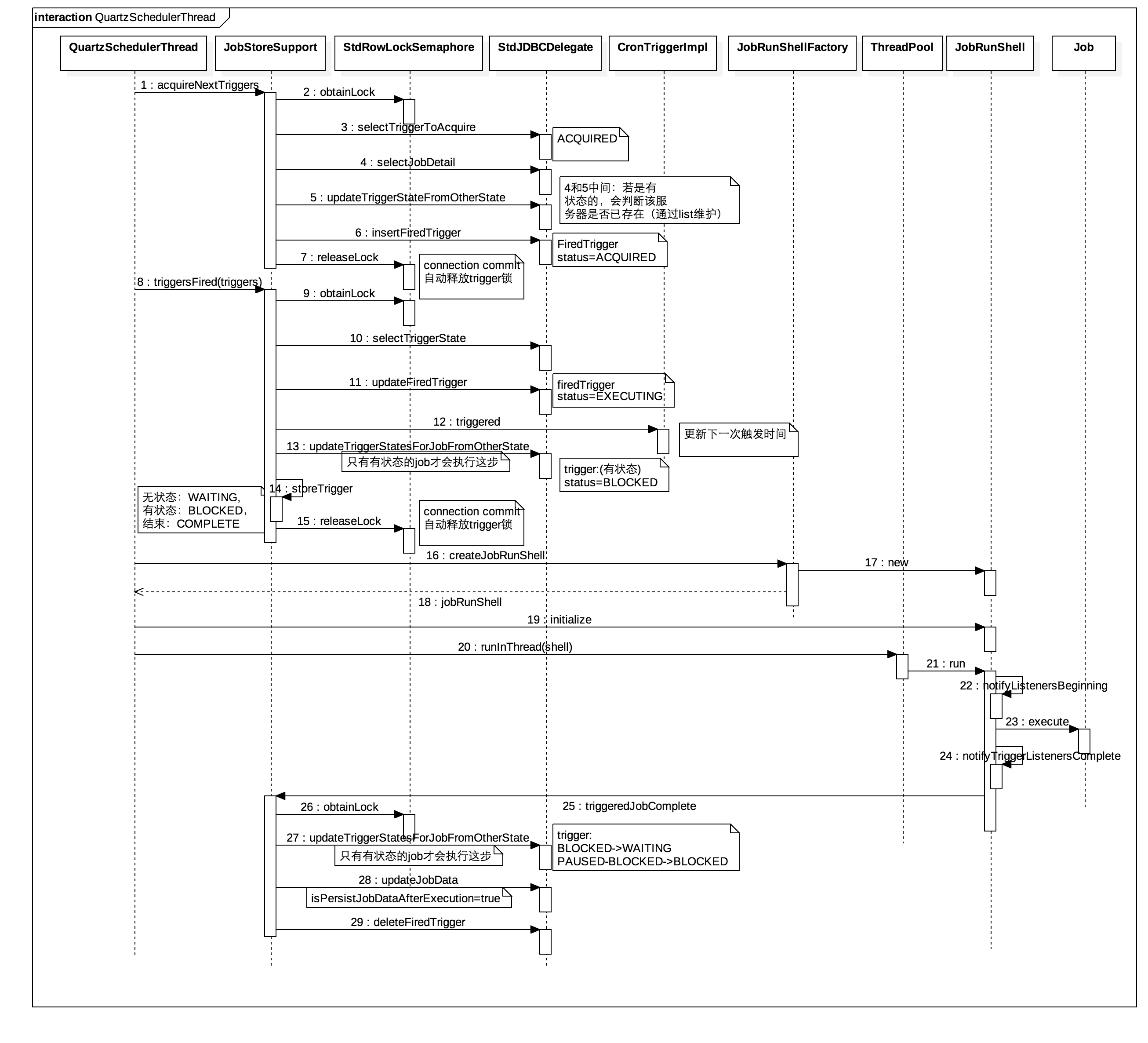
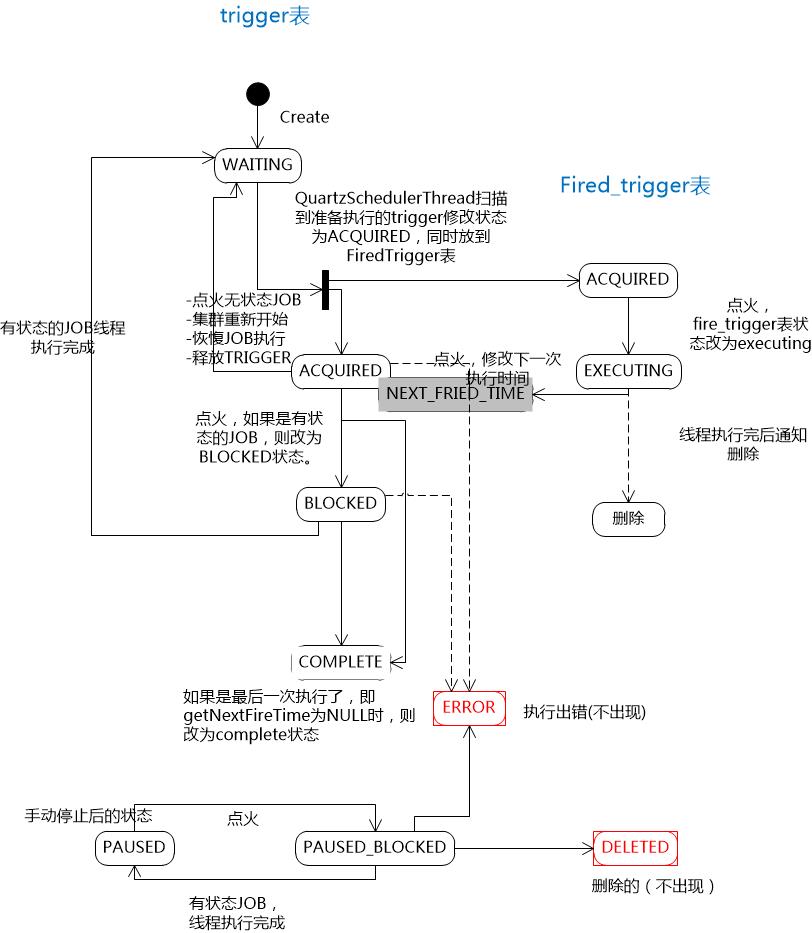
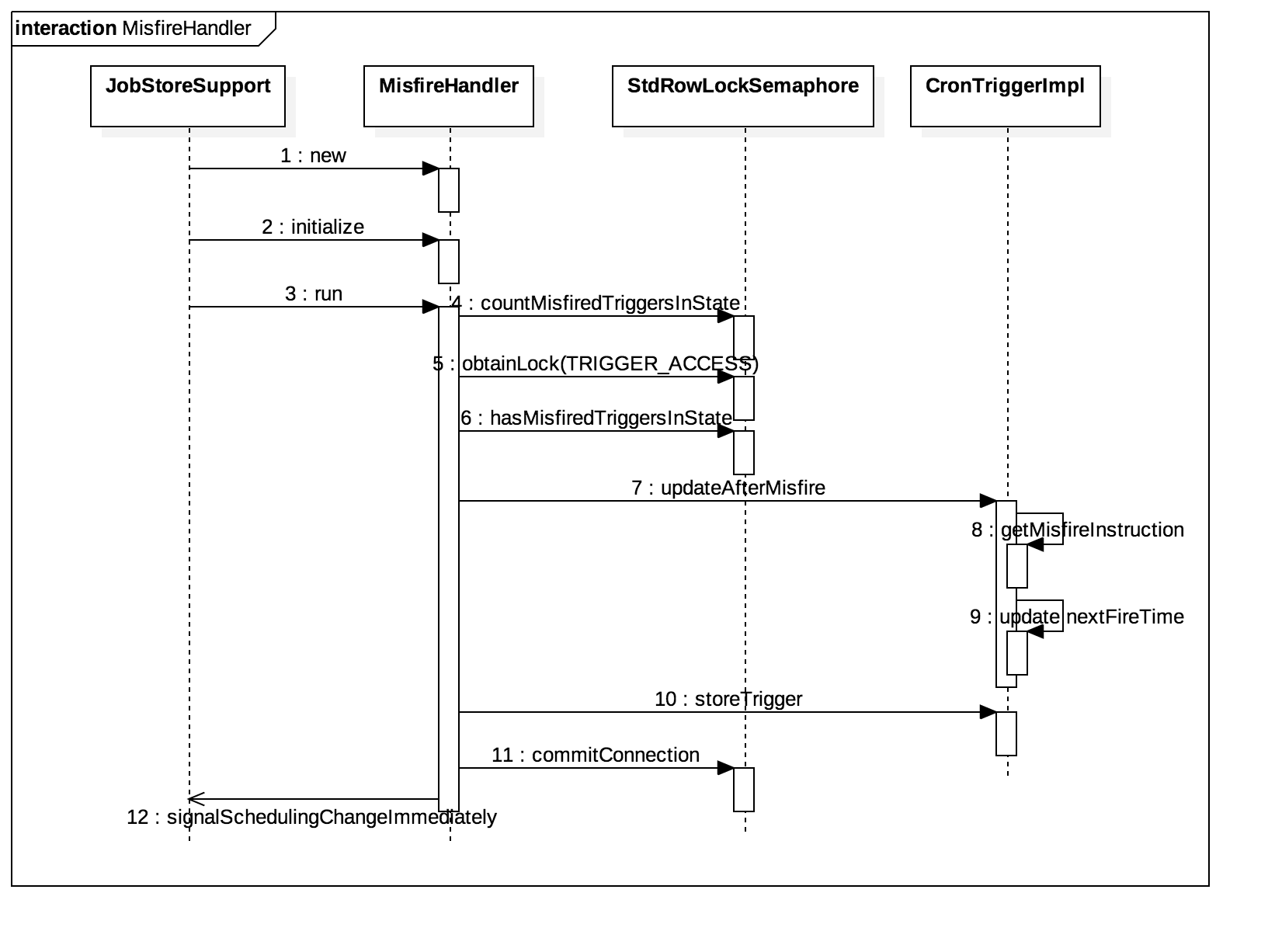
语句1: INSERT tbl_log(buss_seq,oper_usr_nm,crt_usr SELECT t.buss_seq, 'tony'as oper_usr_nm, 'tony'as crt_usr FROM tbl_form_dtl t where t.form_no = ? AND t.buss_st= ? AND t.itct_st= ?
语句2: update tbl_form_dtl a set a.BUSS_ST= '1',a.UPDATE_TM=now(),a.UPDATE_USR = 'tony' where a.form_no= ? AND a.buss_st= ? AND a.itct_st= ?
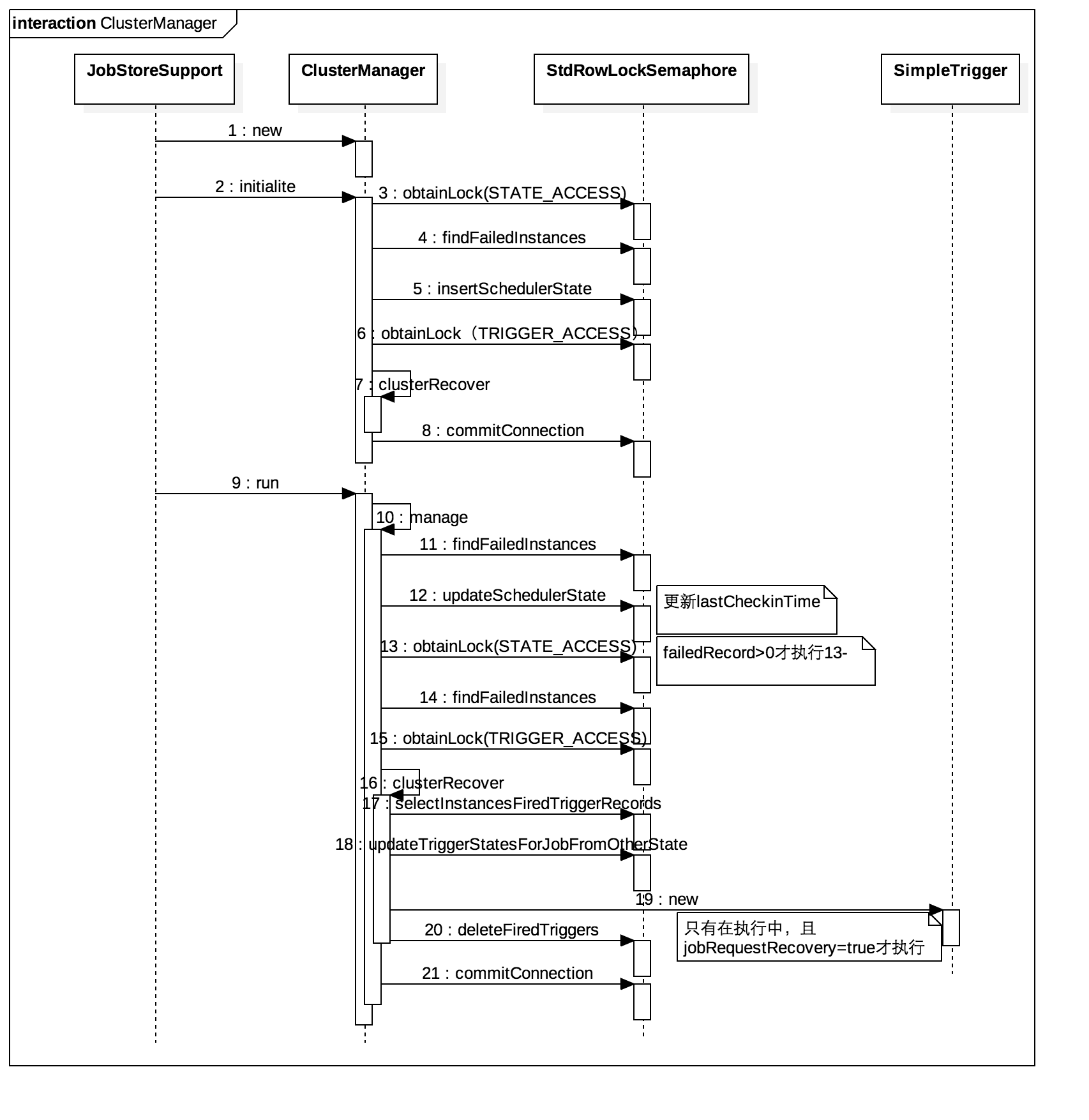
RECORD LOCKS space id 439657 page no 12 n bits 120 index PRIMARY of table databasename.tbl_form_dtl trx id 54562223 lock_mode X waiting
RECORD LOCKS space id 439657 page no 12 n bits 120 index PRIMARY of table databasename.tbl_form_dtl trx id 54562222 lock_mode X
RECORD LOCKS space id 439657 page no 2317 n bits 120 index PRIMARY of table databasename.tbl_form_dtl trx id 54562222 lock_mode X waiting
产生死锁的原因: 事务54562222在执行语句2时,占有了page no =12的X锁,要获取page no=2317的X锁,而该锁已被事务54562223锁住; 事务54562223在执行语句1时,在锁住二级索引时,也获取了page no = 2317的S锁,然后执行语句2,要获取page no = 12的锁,而该锁已被事务54562222锁住。
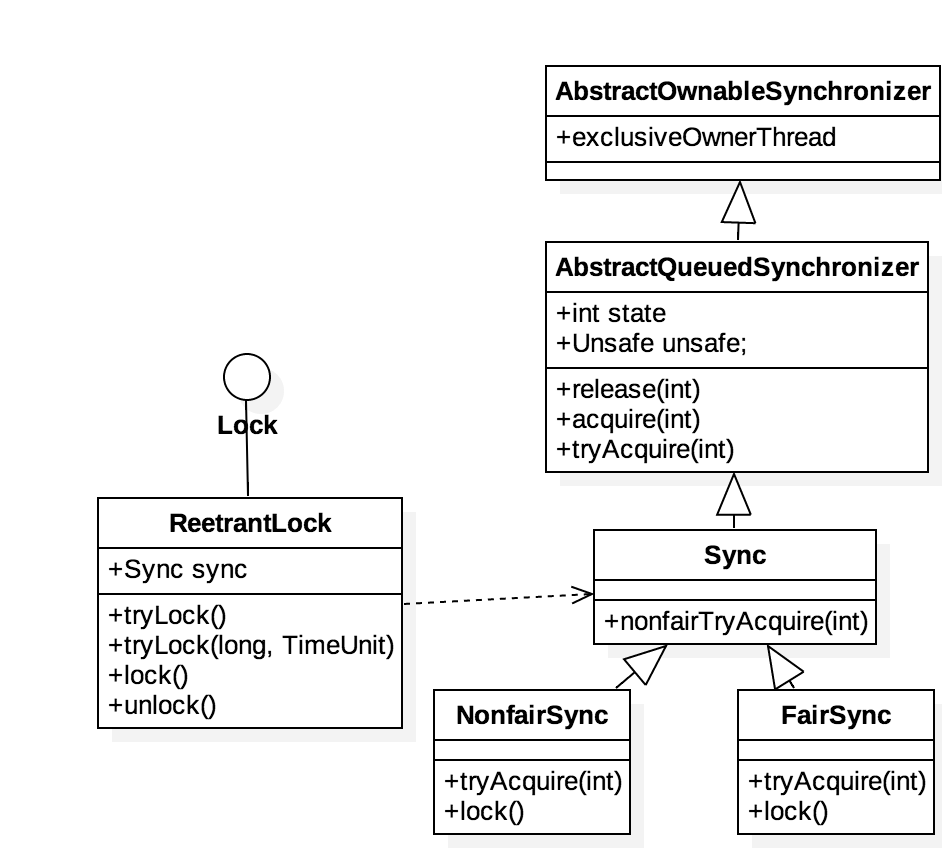
AQS底层调用了很多Unsafe类里的方法来进行并发的处理,Unsafe类里的方法基本都是native的,通过利用系统硬件的支持,来实现并发的控制。其中利用到硬件的最重要的一个指令是CAS(compare and swap),CAS包含了3个操作数:需要读写的内存位置V、进行比较的值A和拟写入的新值B,当且仅当V的值等于A时,CAS才会通过原子方式用新值B来更新V的值,否则不会执行任何操作。
//NonfairSync finalvoidlock(){ if (compareAndSetState(0, 1)) setExclusiveOwnerThread(Thread.currentThread()); else acquire(1); }
//AQS publicfinalvoidacquire(int arg){ //尝试获取锁,如果没获取到,放入等待队列中,同时调用acquireQueued尝试park,挂起线程 if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt();//如果是因为被中断而unpark的,就使线程中断 } //FaireSync protectedfinalbooleantryAcquire(int acquires){ final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { //如果当前锁刚好空着,且队列前面没有在排队的,通过尝试更改state获取锁,获取锁后将exclusiveOwnerThread设为当前线程 if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); returntrue; } }elseif(current == getExclusiveOwnerThread()) {//可重入锁 int nextc = c + acquires; if (nextc < 0) thrownew Error("Maximum lock count exceeded"); setState(nextc); returntrue; } returnfalse; } //NonfairSync protectedfinalbooleantryAcquire(int acquires){ return nonfairTryAcquire(acquires); } finalbooleannonfairTryAcquire(int acquires){ final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { //不公平锁,直接尝试更改state来获取锁,不查看是否有其它线程在队列等待获取锁 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); returntrue; } }elseif(current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow thrownew Error("Maximum lock count exceeded"); setState(nextc); returntrue; } returnfalse; }
//AQS //返回线程是否被中断 finalbooleanacquireQueued(final Node node, int arg){ boolean failed = true; try { boolean interrupted = false; for (;;) { //node的前驱节点 final Node p = node.predecessor(); //如果node的前驱节点为head(head为当前占有锁的节点),则下一个获取锁的节点就是node,尝试获取锁,获取到锁后更改head为node if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } //如果node的前驱节点p的waitStatus为SIGNAL,表示p已被设置为:在release时,要通知后继节点(节点p对应的线程在执行release时,会unpark后继节点),因此p的后继节点node可以安心的park了,因此在parkAndCheckInterrupt方法里调用了LockSupport.park来使线程不被调度(park后,只有在被其它线程unpark或interrupt等情况时才恢复执行);unpark函数可以先于park调用。比如线程B调用unpark函数,给线程A发了一个“许可”,那么当线程A调用park时,它发现已经有“许可”了,那么它会马上再继续运行,所以在上面tryAcquire到下面代码park之间,不用担心因为其它线程释放了锁,而导致当前线程park后一直无法unpark的问题 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } }
//AQS //如果node的前驱节点pred的waitStatus为SINGAL,表示pred在release会unparkpred的后继节点node,因此node可以安心park;如果waitStatus>0表示已经被取消,将node的前驱节点指向前面最近的未被取消的节点;否则将前驱节点waitStatus设置为SIGNAL,调用者需要再尝试获取锁,获取不到再park privatestaticbooleanshouldParkAfterFailedAcquire(Node pred, Node node){ int ws = pred.waitStatus; if (ws == Node.SIGNAL) /* * This node has already set status asking a release * to signal it, so it can safely park. */ returntrue; if (ws > 0) { /* * Predecessor was cancelled. Skip over predecessors and * indicate retry. */ do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { /* * waitStatus must be 0 or PROPAGATE. Indicate that we * need a signal, but don't park yet. Caller will need to * retry to make sure it cannot acquire before parking. */ compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } returnfalse; }
// publicvoidunlock(){ sync.release(1); } //AQS publicfinalbooleanrelease(int arg){ if (tryRelease(arg)) {//tryRelease只更改status和持有锁的线程变量,不用更改head,在acquireQueued中会更改 Node h = head; if (h != null && h.waitStatus != 0) unparkSuccessor(h); returntrue; } returnfalse; } //AQS privatevoidunparkSuccessor(Node node){ /* * If status is negative (i.e., possibly needing signal) try * to clear in anticipation of signalling. It is OK if this * fails or if status is changed by waiting thread. */ int ws = node.waitStatus; if (ws < 0) compareAndSetWaitStatus(node, ws, 0);
/* * Thread to unpark is held in successor, which is normally * just the next node. But if cancelled or apparently null, * traverse backwards from tail to find the actual * non-cancelled successor. */ Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } //唤醒队列的后续节点,如果是共享锁,后继节点会递归的唤醒自己的后继节点 if (s != null) LockSupport.unpark(s.thread); } publicbooleantryLock(){ return sync.nonfairTryAcquire(1); }
publicfinalvoidawait()throws InterruptedException { if (Thread.interrupted()) thrownew InterruptedException(); Node node = addConditionWaiter();//创建waitStatus=CONDITION的node,添加到Condition自己维护的链表中 int savedState = fullyRelease(node);//释放锁;在执行await之前,都需要调用ReentrantLock的lock,await时需要释放持有的锁 int interruptMode = 0; //释放完当前线程占有的锁后,便利AQS队列,看当前节点是否在队列中,如果不在,说明它还没有竞争锁的资格,继续park,直到它被加入到队列中。被加入到队列中是在其它线程调用signal的时候。 while (!isOnSyncQueue(node)) { LockSupport.park(this); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } //被其它线程调用signal唤醒后,重新开始竞争锁 if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) // clean up if cancelled unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); }
publicfinalvoidsignal(){ if (!isHeldExclusively()) thrownew IllegalMonitorStateException(); Node first = firstWaiter; if (first != null) doSignal(first);//唤醒Condition等待队列的第一个节点 } privatevoiddoSignal(Node first){ do { if ( (firstWaiter = first.nextWaiter) == null) lastWaiter = null; first.nextWaiter = null; //将老的头节点,加入到AQS等待队列中 } while (!transferForSignal(first) && (first = firstWaiter) != null); } finalbooleantransferForSignal(Node node){ /* * If cannot change waitStatus, the node has been cancelled. */ if (!compareAndSetWaitStatus(node, Node.CONDITION, 0)) returnfalse;
/* * Splice onto queue and try to set waitStatus of predecessor to * indicate that thread is (probably) waiting. If cancelled or * attempt to set waitStatus fails, wake up to resync (in which * case the waitStatus can be transiently and harmlessly wrong). */ Node p = enq(node); int ws = p.waitStatus; if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL)) LockSupport.unpark(node.thread); returntrue; }
protectedfinalinttryAcquireShared(int unused){ /* * Walkthrough: * 1. If write lock held by another thread, fail. * 2. Otherwise, this thread is eligible for * lock wrt state, so ask if it should block * because of queue policy. If not, try * to grant by CASing state and updating count. * Note that step does not check for reentrant * acquires, which is postponed to full version * to avoid having to check hold count in * the more typical non-reentrant case. * 3. If step 2 fails either because thread * apparently not eligible or CAS fails or count * saturated, chain to version with full retry loop. */ Thread current = Thread.currentThread(); int c = getState(); //status的低16位表示写锁的计数,低16位不等于0表示现在有进程持有写锁,其他线程不能获取锁,不过同一个线程在持有写锁的情况下,如果等待队列的第一个节点(head的后继节点)不是等待写锁,那么可以获取读锁 if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current) return -1; int r = sharedCount(c); //公平锁在要获取读锁时,如果已经有线程在等待队列等待,则不能抢占;非公平锁在等待队列的第一个线程不是等待写锁的话,且当前没有线程占有写锁,则可以直接抢占读锁 if (!readerShouldBlock() && r < MAX_COUNT && compareAndSetState(c, c + SHARED_UNIT)) {//读锁的计数用status的高16位表示 if (r == 0) { firstReader = current; firstReaderHoldCount = 1; } elseif(firstReader == current){ firstReaderHoldCount++; } else { HoldCounter rh = cachedHoldCounter; if (rh == null || rh.tid != current.getId()) cachedHoldCounter = rh = readHolds.get(); elseif(rh.count == 0) readHolds.set(rh); rh.count++; } return1; } return fullTryAcquireShared(current); }
protectedfinalbooleantryAcquire(int acquires){ /* * Walkthrough: * 1. If read count nonzero or write count nonzero * and owner is a different thread, fail. * 2. If count would saturate, fail. (This can only * happen if count is already nonzero.) * 3. Otherwise, this thread is eligible for lock if * it is either a reentrant acquire or * queue policy allows it. If so, update state * and set owner. */ Thread current = Thread.currentThread(); int c = getState(); int w = exclusiveCount(c); if (c != 0) { // (Note: if c != 0 and w == 0 then shared count != 0) if (w == 0 || current != getExclusiveOwnerThread()) returnfalse; if (w + exclusiveCount(acquires) > MAX_COUNT) thrownew Error("Maximum lock count exceeded"); // Reentrant acquire setState(c + acquires); returntrue; } ////获取写锁时,如果当前读写锁都没有被占有,公平锁会根据是否等待队列前面有等待的线程来判断能否获取写锁,非公平锁则直接获取写锁 if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) returnfalse; setExclusiveOwnerThread(current); returntrue; }
privatevoiddoAcquireShared(int arg){ final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0) { //获取到锁后,修改head为当前的node,并将后继等待读锁的也唤醒,唤醒是递归的 setHeadAndPropagate(node, r); p.next = null; // help GC if (interrupted) selfInterrupt(); failed = false; return; } } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } privatevoidsetHeadAndPropagate(Node node, int propagate){ Node h = head; // Record old head for check below setHead(node); /* * Try to signal next queued node if: * Propagation was indicated by caller, * or was recorded (as h.waitStatus either before * or after setHead) by a previous operation * (note: this uses sign-check of waitStatus because * PROPAGATE status may transition to SIGNAL.) * and * The next node is waiting in shared mode, * or we don't know, because it appears null * * The conservatism in both of these checks may cause * unnecessary wake-ups, but only when there are multiple * racing acquires/releases, so most need signals now or soon * anyway. */ if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0) { Node s = node.next; if (s == null || s.isShared()) doReleaseShared();//如果后继节点是shared的,唤醒它 } } privatevoiddoReleaseShared(){ /* * Ensure that a release propagates, even if there are other * in-progress acquires/releases. This proceeds in the usual * way of trying to unparkSuccessor of head if it needs * signal. But if it does not, status is set to PROPAGATE to * ensure that upon release, propagation continues. * Additionally, we must loop in case a new node is added * while we are doing this. Also, unlike other uses of * unparkSuccessor, we need to know if CAS to reset status * fails, if so rechecking. */ for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } elseif(ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }
registers a RequestMappingHandlerMapping, a RequestMappingHandlerAdapter, and an ExceptionHandlerExceptionResolver (among others) in support of processing requests with annotated controller methods using annotations such as @RequestMapping, @ExceptionHandler, and others.
It also enables the following:
Spring 3 style type conversion through a ConversionService instance in addition to the JavaBeans PropertyEditors used for Data Binding.
Support for formatting Number fields using the @NumberFormat annotation through the ConversionService.
Support for formatting Date, Calendar, Long, and Joda Time fields using the @DateTimeFormat annotation.
Support for validating @Controller inputs with @Valid, if a JSR-303 Provider is present on the classpath.
HttpMessageConverter support for @RequestBody method parameters and @ResponseBody method return values from @RequestMapping or @ExceptionHandler methods.
This is the complete list of HttpMessageConverters set up by mvc:annotation-driven:
ResourceHttpMessageConverter converts to/from org.springframework.core.io.Resource for all media types.
SourceHttpMessageConverter converts to/from a javax.xml.transform.Source.
FormHttpMessageConverter converts form data to/from a MultiValueMap.
Jaxb2RootElementHttpMessageConverter converts Java objects to/from XML — added if JAXB2 is present and Jackson 2 XML extension is not present on the classpath.
MappingJackson2HttpMessageConverter converts to/from JSON — added if Jackson 2 is present on the classpath.
MappingJackson2XmlHttpMessageConverter converts to/from XML — added if Jackson 2 XML extension is present on the classpath.
AtomFeedHttpMessageConverter converts Atom feeds — added if Rome is present on the classpath.
RssChannelHttpMessageConverter converts RSS feeds — added if Rome is present on the classpath.
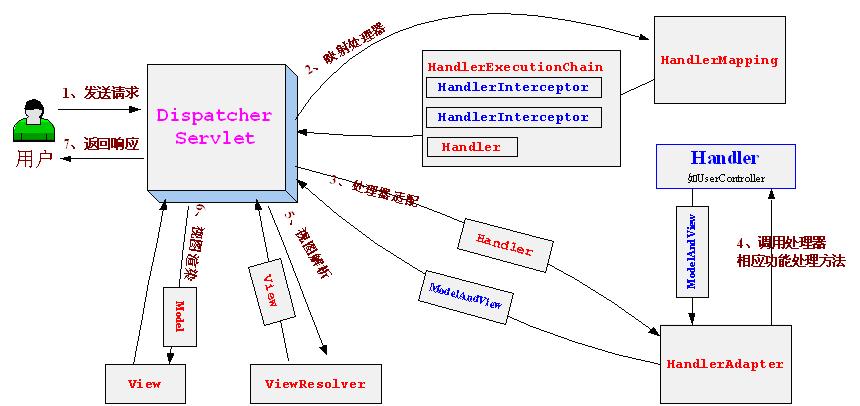
//步骤3、处理器适配,即将我们的处理器包装成相应的适配器(从而支持多种类型的处理器) HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Process last-modified header, if supported by the handler. String method = request.getMethod(); boolean isGet = "GET".equals(method); if (isGet || "HEAD".equals(method)) { long lastModified = ha.getLastModified(request, mappedHandler.getHandler()); if (logger.isDebugEnabled()) { String requestUri = urlPathHelper.getRequestUri(request); logger.debug("Last-Modified value for [" + requestUri + "] is: " + lastModified); } if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) { return; } }
//执行处理器相关的拦截器的预处理(HandlerInterceptor.preHandle) if (!mappedHandler.applyPreHandle(processedRequest, response)) { return; }
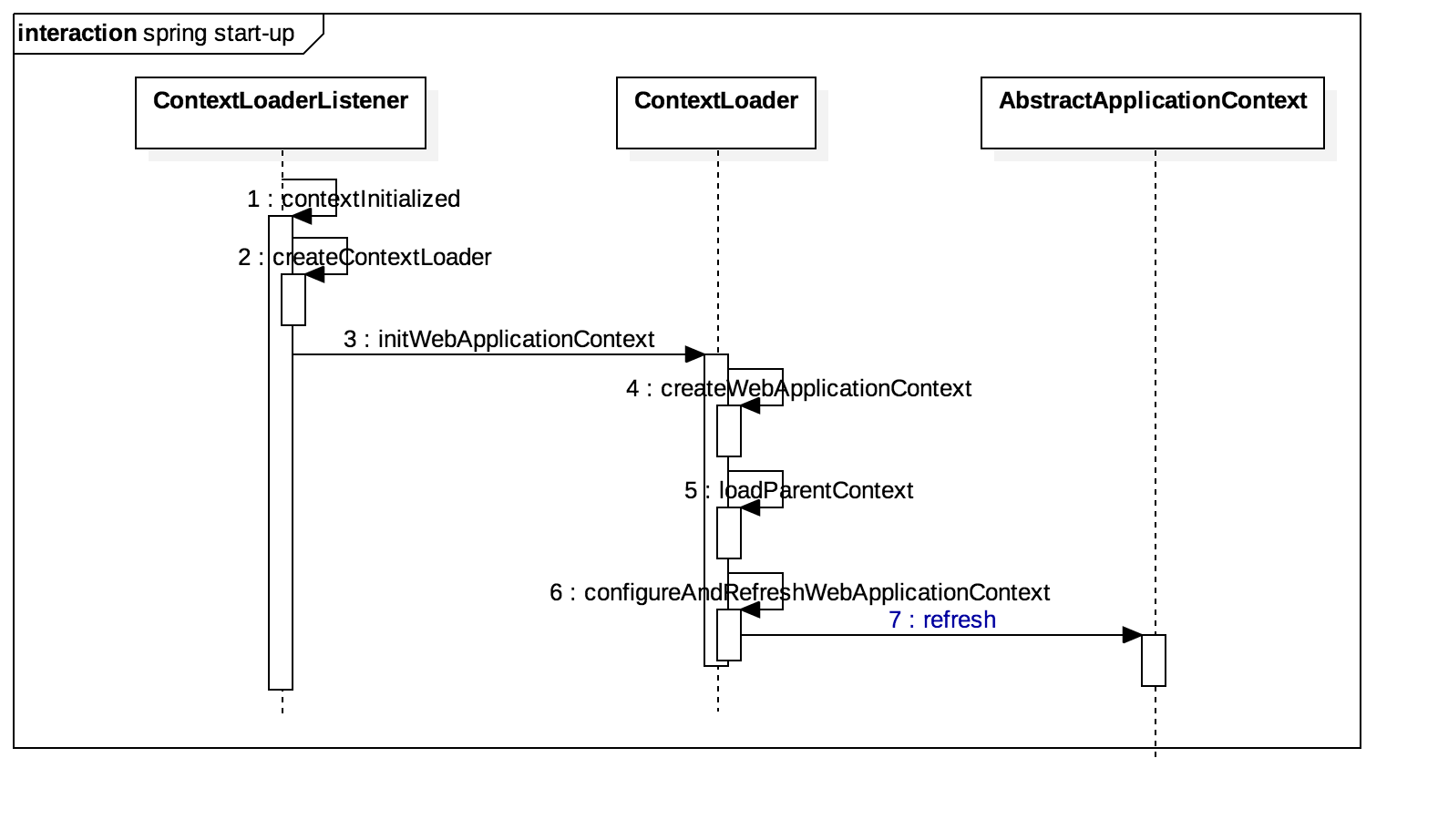
publicvoidrefresh(){ // Prepare this context for refreshing. prepareRefresh();
// Tell the subclass to refresh the internal bean factory. ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context. prepareBeanFactory(beanFactory); // 注册实现了BeanPostProcessor接口的bean postProcessBeanFactory(beanFactory);
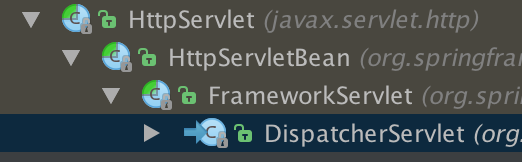
HttpServletBean继承HttpServlet,因此在Web容器启动时将调用它的init方法,该初始化方法的主要作用: a. 将Servlet初始化参数(init-param)设置到该组件上(如contextAttribute、contextClass、namespace、contextConfigLocation),通过BeanWrapper简化设值过程,方便后续使用; b. 提供给子类初始化扩展点,initServletBean(),该方法由FrameworkServlet覆盖。
FrameworkServlet继承HttpServletBean,通过initServletBean()进行Web上下文初始化,该方法主要覆盖一下两件事情: a. 初始化web上下文; b. 提供给子类初始化扩展点;
bind connect write flush read disconnect close deregister
例如,有一个称为p的ChannelPipeline,添加了如下的handler:
1 2 3 4 5
p.addLast("1", new InboundHandlerA()); p.addLast("2", new InboundHandlerB()); p.addLast("3", new OutboundHandlerA()); p.addLast("4", new OutboundHandlerB()); p.addLast("5", new InboundOutboundHandlerX());
OS-level zero copy involves avoiding copying memory blocks from one location to another (typically from user space to kernel space) before sending data to the hardware driver (network card or disk drive) or vice versa.
Netty zero copy is talking about optimizing data manipulation on Java level (user-space only). Their ChannelBuffer allows to read contents of multiple byte buffers without actually copying their content.
In other words, while Netty works only in user space, it is still valid to call their approach “zero copy”. However, if OS does not use or support true zero copy, it is possible that when data created by Netty-powered program will be sent over the network, data would still be copied from user space to kernel space, and thus true zero-copy would not be achieved.
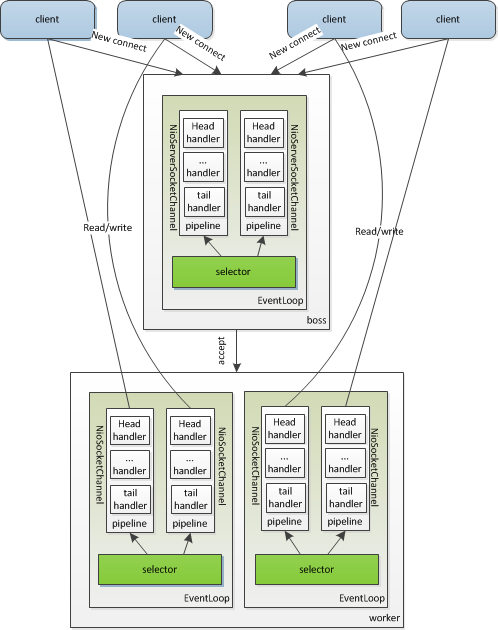
EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .option(ChannelOption.SO_BACKLOG, 100) .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override publicvoidinitChannel(SocketChannel ch)throws Exception { ChannelPipeline p = ch.pipeline(); if (sslCtx != null) { p.addLast(sslCtx.newHandler(ch.alloc())); } //p.addLast(new LoggingHandler(LogLevel.INFO)); p.addLast(new EchoServerHandler()); } });
// Start the server. ChannelFuture f = b.bind(PORT).sync(); // Wait until the server socket is closed. f.channel().closeFuture().sync(); } finally { // Shut down all event loops to terminate all threads. bossGroup.shutdownGracefully(); workerGroup.shutdownGracefully(); }
// Configure the client. EventLoopGroup group = new NioEventLoopGroup(); try { Bootstrap b = new Bootstrap(); b.group(group) .channel(NioSocketChannel.class) .option(ChannelOption.TCP_NODELAY, true) .handler(new ChannelInitializer<SocketChannel>() { @Override publicvoidinitChannel(SocketChannel ch)throws Exception { ChannelPipeline p = ch.pipeline(); if (sslCtx != null) { p.addLast(sslCtx.newHandler(ch.alloc(), HOST, PORT)); } //p.addLast(new LoggingHandler(LogLevel.INFO)); p.addLast(new EchoClientHandler()); } });
// Start the client. ChannelFuture f = b.connect(HOST, PORT).sync();
// Wait until the connection is closed. f.channel().closeFuture().sync(); } finally { // Shut down the event loop to terminate all threads. group.shutdownGracefully(); }
客户端调用rest service jersey提供了客户端API,可以方便的调用service。当然,在JAX-RS2中,也提供了客户端的API。通过jersey的客户端API调用方式如下:
1 2 3 4 5
Client c = Client.create(); WebResource r = c.resource("http://localhost:8080/rest-jersey-demo/library..."); ClientResponse response = r.get(ClientResponse.class); int status = response.getStatus(); String entity = response.getEntity(String.class);
JAX-RS(Java API for RESTful Web Service,JSR-311)是Java提供用于开发RESTful Web服务基于注解(annotation)的API,在Java EE 6中发布,旨在定义一个统一的规范,使得Java程序员可以使用一套固定的接口来开发REST应用,避免了依赖第三方框架,同时JAX-RS使用POJO编程模型和基于注解的配置并集成JAXB,从而有效缩短了REST应用的开发周期,JSR-311开始于2007年2月,至今发布了两个最终版本1.0,1.1。Java EE7已经发布并且包含了最新的JAX-RS 2.0版本,它是Marek Potociar和Santiago Pericas-Geertsen领导的JSR-339实现。JAX-RS2.0主要的新特性包括:客户端API、异步、HATEOAS(超媒体)、注解、校验、过滤器和处理器(Handler)、内容协商。
HATEOAS(超媒体) HATEOAS(Hypermedia as the Engine of Application State,超媒体作为应用程序状态引擎)需要RESTful的生产者和消费者在每次调用时返回一组达成共识的链接,它用于导航到下一个步骤。如果你将REST视为Web页面的应用版本,那么HATEOAS可以视为Web页面中的链接。 JAX-RS 2.0提供了Link和Target类,它们用于服务器端在响应中引入超链接并在客户端对其进行响应。
REST 是英文 Representational State Transfer 的缩写,有中文翻译为“具象状态传输”。REST 这个术语是由 Roy Fielding 在他的博士论文 《 Architectural Styles and the Design of Network-based Software Architectures 》中提出的。REST 并非标准,而是一种开发 Web 应用的架构风格,可以将其理解为一种设计模式。REST 基于 HTTP,URI,以及 XML 这些现有的广泛流行的协议和标准,伴随着 REST,HTTP 协议得到了更加正确的使用。
相较于基于 SOAP 和 WSDL 的 Web 服务,REST 模式提供了更为简洁的实现方案。目前,越来越多的 Web 服务开始采用 REST 风格设计和实现,真实世界中比较著名的 REST 服务包括:Google AJAX 搜索 API、Amazon Simple Storage Service (Amazon S3)等。REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
基于 REST 的 Web 服务遵循一些基本的设计原则:
网络上的所有事物都被抽象为资源;
系统中的每一个对象或是资源都可以通过一个唯一的 URI 来进行寻址,URI 的结构应该简单、可预测且易于理解,比如定义目录结构式的 URI;
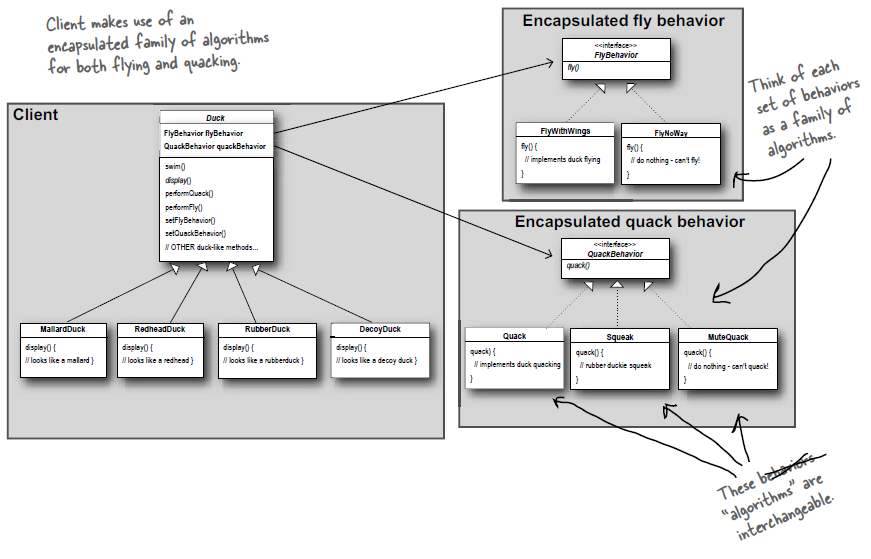
publicclassRedHeadDuckextendsDuck{ publicRedHeadDuck(){ flyBehavior = new FlyWithWings(); quackBehavior = new Quack(); } publicvoiddisplay(){ System.out.println("I'm a real Red Headed duck"); } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
publicclassMiniDuckSimulator{ publicstaticvoidmain(String[] args){ MallardDuck mallard = new MallardDuck(); RubberDuck rubberDuckie = new RubberDuck(); DecoyDuck decoy = new DecoyDuck(); ModelDuck model = new ModelDuck();